Categories
Applying the Swiss Cheese Model to Survey Fraud
The Swiss Cheese Model of Pandemic Defense applied to survey fraud.
This will not come as a surprise: An article published in GreenBook about how to improve data quality in market research highlighted the fact that there is no single solution for detecting and preventing survey fraud. Of course not! It would never be that easy. Instead, we have to approach the problem by thinking of it in terms of layers of protection that we implement throughout the research process, all the way from design, through execution, to analysis.
This is similar to the Swiss Cheese Model of Pandemic Defense, a metaphor that describes how cheese slices represent multiple layers of protection that can be employed to avoid contracting COVID-19. Similarly, the Swiss Cheese model can be applied to preventing survey fraud. While no individual layer of protection – fraud prevention and detection software, the screener, the Main questionnaire, and post-fieldwork data cleaning – is perfect, we have the best chance of preventing survey fraud when we apply all the layers together.
While this is a good analogy, the issue with the Swiss Cheese metaphor is that each slice appears to contribute equally to preventing the virus when, in fact, some of the layers provide more protection than others. In our metaphor, we’ve designed each slice of cheese to proportionally represent the (unequal) role they play in preventing fraud.
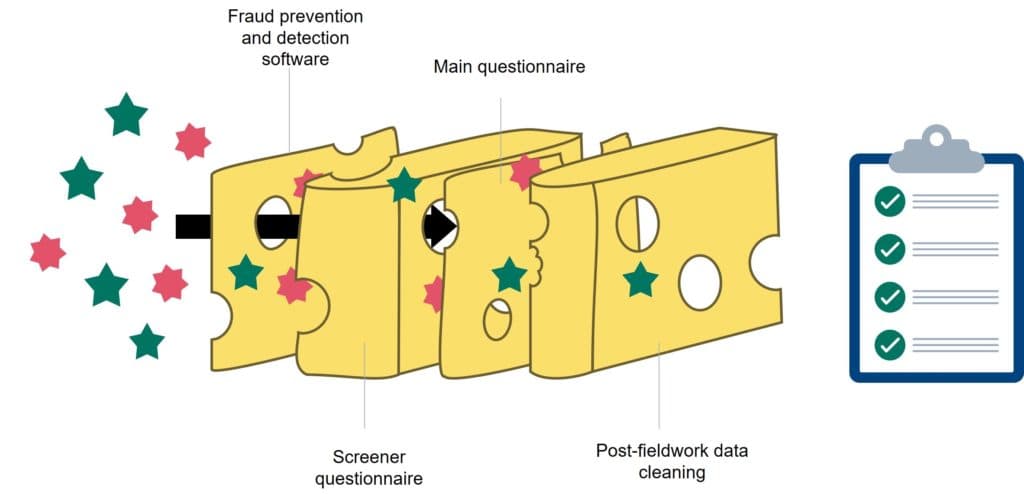
ADAPTED FROM IAN M. MACKAY AND JAMES T. REASON. ILLUSTRATION BY 2CV RESEARCH.
How to use all the cheese slices
What follows are some of the best practices we employ as we consider fraud prevention in each step of the research process.
1. Fraud prevention and detection software has limits
Most sample providers have software (some sophisticated, some basic, and some can even block good respondents) that utilizes passive machine data and behavioral data to combat fraud technologies. These tools flag and remove both duplicates and fraudsters before they enter your survey. While this first slice should be the thickest one, it does not always work that way in practice. Over time, some of these tools have become more refined at blocking more sophisticated fraud, but bad actors are continually trying to figure out ways around this technology. Further, the threshold (i.e. quality score) set to determine the outcome of suspicious respondents is something the panel providers decide. Because the panel providers need to balance sample quality with survey traffic, their priorities regarding those thresholds might be different from yours.
2. Designing tanks, not screeners
Considering the limitations of anti-fraud survey solutions, the thickest, most important layer of protection is your screener. The screener is also critically important for lower incidence consumer and B2B work. This is where it is easiest to identify individuals who maliciously try to qualify for your survey. As such, screeners need to be designed like tanks, bulletproof and tough, but also smart and subtle, using quality assurance (QA) “traps” that are not blatantly obvious to fraudsters. For example, most fraudsters will not be fooled by fake brands.
3. Fraudsters blend in
Once fraudsters have qualified to take your survey, they easily blend into your dataset. They know what researchers look for and they are able to skillfully avoid most traps. For this reason, the main questionnaire is another thin slice of cheese. Here, the common QA traps you’ve set up will mainly work to identify real humans who are not paying attention, not bots. If you have a large sample size, this is arguably a small number of people who have little impact on the overall story.
4. Post-fieldwork data cleaning: Time-consuming, but necessary
Aside from the screener, this is where researchers have the most control. When data collection is near-complete, researchers are able to see the full picture. Patterns in the data emerge. Outliers stand out. Data that earlier seemed sensible now raises questions from within a broader context. As much as we would like to automate the entire data-cleaning process, this is where human intelligence and intuition are vital in recognizing fraud.
At this stage, it is critical to have a solid relationship with a panel partner who shares your concerns about data quality, and who trusts your expertise. Any bad respondents must be removed from your dataset and replaced, so having a panel partner that will not turn this process into a long negotiation is worth their weight in gold. Find a partner you can rely on to keep an already time-consuming process short.
Always add extra cheese
Preventing and identifying survey fraud is time-consuming, but is an absolute necessity for any organization that relies on good quality data to make decisions. Understanding the role and effectiveness of each slice of cheese, or layer of protection, can help researchers spend less time cleaning data and more time doing what we love: discovering and sharing insights.
The take-away? Always ask for extra cheese, both metaphorically and literally!
Comments
Comments are moderated to ensure respect towards the author and to prevent spam or self-promotion. Your comment may be edited, rejected, or approved based on these criteria. By commenting, you accept these terms and take responsibility for your contributions.
Disclaimer
The views, opinions, data, and methodologies expressed above are those of the contributor(s) and do not necessarily reflect or represent the official policies, positions, or beliefs of Greenbook.
More from Karine Pepin
Truth To Be Told: Five Realities About Online Sample That Compromise Data Quality
Explore five key truths about sampling, uncovering fraud, low-quality respondents, and transparency issues that have eroded data quality over two deca...
From Deliverables to Research Assets: How Insights Teams Can Leverage Content Design Principles for Greater Influence
Learn key principles of content design that enable researchers to distill insights into assets, fostering stakeholder influence and sustainable busine...
The Cost of Being Wrong: How Overconfidence in Ineffective AI Detection Tools Impacts the Research Ecosystem
Discover the challenge of identifying AI-generated open-ended responses and the potential consequences for researchers and the market research industr...
Why the Sampling Ecosystem Sets Up Honest Participants for Failure
This article discusses how the online sampling ecosystem favors professional respondents and bad actors. It advocates for a transformative shift towar...
ARTICLES
Top in Research Methodologies
Future Trends Emerging in Mixed-Method Marketing Research
Explore the future of mixed-method marketing research, including AI, synthetic data, continuous insights, and evolving research workflows.
Ashley Shedlock
Content Producer at Greenbook
When Easy Becomes Empty: The Frictionless Feedback Fallacy
Making surveys easier doesn’t always improve insights. Discover why thoughtful feedback design balances convenience with meaningful, reflective respon...
Tarik Covington
Founder & Chief Strategist at Covariate. Human-Centered Insights
The Always-on Agency: How to Survive the Shift to Intelligence-Native Organizations
The insight agency model is under pressure. In an always-on world, success depends on becoming a decision partner, not just a supplier of research pro...
Hannah Mann
Founding Partner at Day One Strategy
The Ambiguity of Frequent Survey Participation: Is “Hyperactivity” a Signal of Professional Fraud?
Learn how to identify engaged respondents, detect bad actors, and improve data quality for more reliable research outcomes.
Sebastian Berger
Head of Science ReDem at Rep Data

Sign Up for
Updates
Get content that matters, written by top insights industry experts, delivered right to your inbox.